
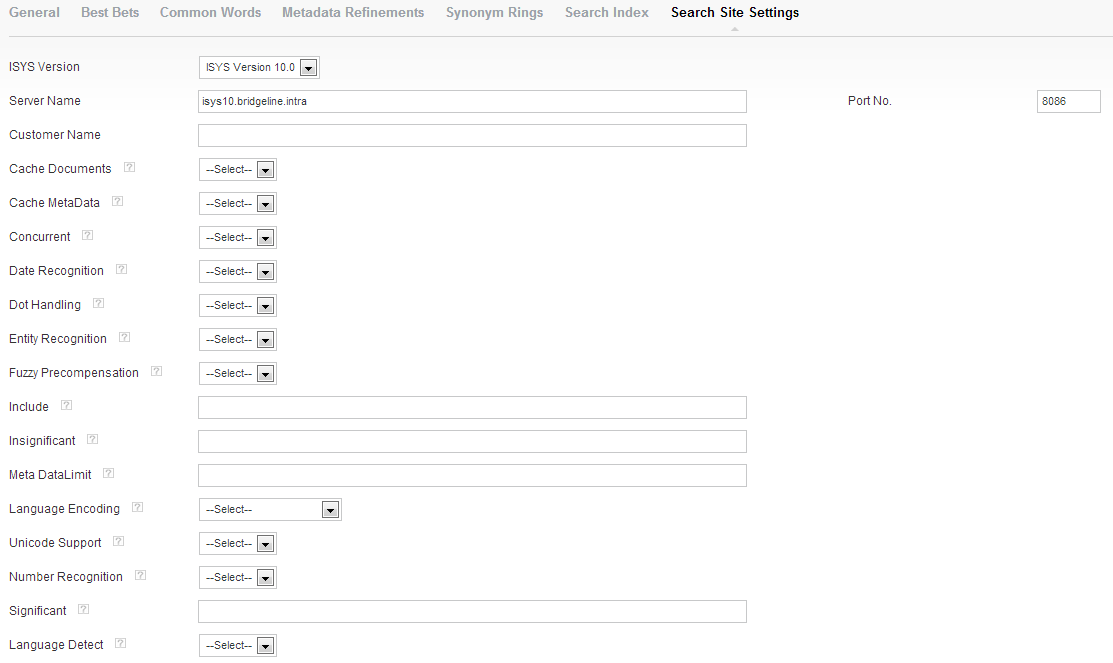
What you see in some of the Search Configuration Screens will vary depending on what version of Search you are using. If the ISYS Version setting is set to 9.7, most configurations or settings will not appear.
You can set the configurations for each index separately. After changing any of the settings you should reindex the site by clicking Reprocess Index.
Changing these settings will be reflected in the ISYS.CFG file on the central Enterprise server, but will not affect the index until reprocessed.
Below are Settings and their uses. If not set, the default is typically false or ignored. The API will only return values that are in the .CFG file, so these should be ignored if not set.
|
Name of Search Site Setting |
Description |
Drop down Options |
|---|---|---|
| Index | Which index is being configured | FrontEnd, Admin, Product, Custom |
|
ISYS Version |
Version of Search being used. If 9.7, none of the options below will appear. |
|
|
Server Name |
Name of Search Server in use |
|
| Port No. | Server Port Number | |
|
Customer Name |
Customer (Website) Name |
|
|
Cache Documents |
Allows document text to be compressed and cached in the index to improve context results and speed up document browsing. |
True/False |
|
Cache MetaData |
Retains a copy of the document metadata in the index for faster retrieval and allows metadata to be used for document categories |
True/False |
|
Concurrent |
Allows updating and queries to be performed simultaneously |
True/False |
|
Date Recognition |
Enables dates to be handled intelligently in queries. Also allows dates to be used in range queries. This will increase the size of and slow the index slightly, although this should not be noticeable unless there are large numbers of dates. There are a large number of valid dates recognized such as 4 15 94 or 15-4-94 or 15-apr-94 or April 15th, 1994, etc. (Regional settings will determine if 4-12 is recognized as December 4 or 12 April. ) |
True/False |
|
Dot Handling |
Allows dots occurring in the middle of a string of characters which appear to be forming a paragraph number (e.g. " 3.2.12") to not be treated as word separators.Dots at the start or end of a word are not considered significant. |
True/False |
|
Entity Recognition |
Specifies the search engine to recognize and index entities (people, organizations, websites, email addresses and locations). The Enterprise Search lexicon can be augmented to include organizations or individuals whose names are not being reliably detected. |
True/False |
|
Fuzzy Precompensation |
Attempts to compensate for OCR and typographical errors in scanned documents. For example, searches for duck would also turn up cluck. This will increase index size and indexing time slightly. You should also notify users when it is in use to avoid confusion. |
True/False |
|
Include |
Points to another index for chaining indexes together. Delimiter – Semicolon “;” Example: \\file-cluster1.objectwareinc.com\ECO1\SharedLibraries\Company\Company_English\CMS\ISYS;\\file-cluster1.objectwareinc.com\ECO1\SharedLibraries\Company_LatinCompany\CMS\ISYS |
|
|
Insignificant |
The list of characters to be considered insignificant. These are individual characters which are part of a word but are not regarded as important. Insignificant characters are treated as if they are invisible. For instance, if the hyphen is made insignificant then words which are hyphenated will be treated as one word, for example post-graduate would be indexed as postgraduate. The default insignificant characters are the apostrophe ('), underscore (_) and single quote (' '). To add new insignificant characters enter it in the insignificant field (without separators). To delete an insignificant character simply delete it from the field. |
|
|
MetaData Limit |
Controls the maximum amount of metadata which will be stored by the CacheMetaData keyword. Defaults to 6kb, and may never exceed 64k per document. |
|
|
Language Encoding |
Specifies the Language Encoding of the Documents in the Index. Selecting Korean, Chinese, Hong Kong Chinese or Japanese enables multi-byte character support in Perceptive Enterprise Search. Note: This will not change the language of the documents being indexed. |
English English Ignore Accents, Korean Chinese, Traditional Chinese Hong Kong Japanese Arabic Chinese Simplified Cyrillic, Greek Turkish Hebrew Vietnamse Baltic |
| Unicode Support | Setting this option indexes all characters as Unicode, using the encoding of the document where available (Formats that specify encoding include Microsoft Office formats and Adobe Acrobat files). For documents that do not specify their encoding, such as text files, the encoding set in LanguageEncoding will be used. This allows a single index to contain documents from multiple languages, e.g. French, Chinese, Russian and English in a single index. Setting this option will lead to larger index file. | True/False |
|
Number Recognition |
Enables numbers to be handled intelligently in queries, including numerical ranges. This option works in similar way to the Intelligent Date recognition option but for numbers only. For example, the number 1,029 could be expressed in any of the following ways and be recognized as being the same. 1029 - 1,029 one thousand and twenty nine - one thousand, twenty nine - 1,029.00 - 1 029 - one zero two nine -a thousand and twenty nine Note: The Index dots when embedded in words or numbers option will be automatically enabled when Intelligent Number recognition is used. |
True/False |
| Significant |
The list of characters to be considered significant. These are individual characters which convey meaning and are an important part of a word. The numbers 0 through 9, the letters A to Z, in both upper and lower case, and the international character set are considered significant and are automatically placed in this category. You may want to specify other characters to suit your purposes. For instance, the dollar sign ($) if you need to search prices. As an example, if the hyphen was made significant then post-graduate would be indexed as post-graduate and a query for postgraduate would not return post-graduate and vice versa. To add new significant characters enter it into the significant field (without separators).To delete a significant character simply delete it from the field. |
|
| Language Detect |
When this option is enabled, Perceptive Enterprise Search will try to determine the language of the document. All documents will have a metadata field called ISYS_LANG injected that stores the ISO 639 2 digit language code. You can then use this value to search on document in a given language, or to refine a result list to a particular language. Sample:
|
True/False |
|
iAPPS is a product of Bridgeline Digital
|

